

Inside the Mind of ChatGPT: How AI Understands and Responds


Welcome to The AI Signal, where algorithms dream, machines learn, and the future unfolds. The edge of tomorrow comes alive in just 5 minutes. This newsletter guides you through AI’s exhilarating and ever-evolving world.

INTRODUCTION
ChatGPT is an advanced AI model designed for natural, conversational interactions. It can answer follow-up questions, address mistakes, challenge incorrect premises, and reject inappropriate requests, making it highly versatile. As a sibling to InstructGPT, ChatGPT is trained to follow prompts and deliver detailed responses, with ongoing user feedback helping to refine its capabilities.

The introduction of ChatGPT seeks to collect user feedback to evaluate its performance and potential. This input will help enhance its strengths and address areas for improvement, ensuring a more robust conversational AI.
Let's Dive into InstructGPT: Unveiling Its Wonders!
InstructGPT is a fine-tuned version of GPT-3 designed to follow user instructions more effectively, truthfully, and safely. Developed using reinforcement learning from human feedback (RLHF), it significantly improves alignment, reducing toxic or untruthful outputs while maintaining GPT-3's advanced capabilities. These models prioritize helpfulness and reliability, setting a new standard for language model alignment and user interaction.
Key Features
Enhanced Instruction Following: Generates responses that better align with user prompts.
Improved Truthfulness: Reduces the frequency of factually incorrect outputs.
Lower Toxicity: Produces less harmful or biased content compared to GPT-3.
Human-in-the-Loop Training: Fine-tuned using RLHF for safer and more reliable outputs.
Efficiency with Fewer Parameters: The 1.3B InstructGPT model often outperforms the larger 175B GPT-3 model.
No Compromise on Capabilities: Retains GPT-3's strength in academic NLP evaluations.
Default Deployment: The standard language model is now available on OpenAI's API.

Quality ratings on a 1–7 scale show that InstructGPT models significantly outperform GPT-3, both with and without few-shot prompting, as well as models fine-tuned with supervised learning. Labelers consistently rate InstructGPT outputs higher for prompts submitted on the API. These results highlight InstructGPT's superior alignment and instruction-following capabilities.
Method for InstructGPT
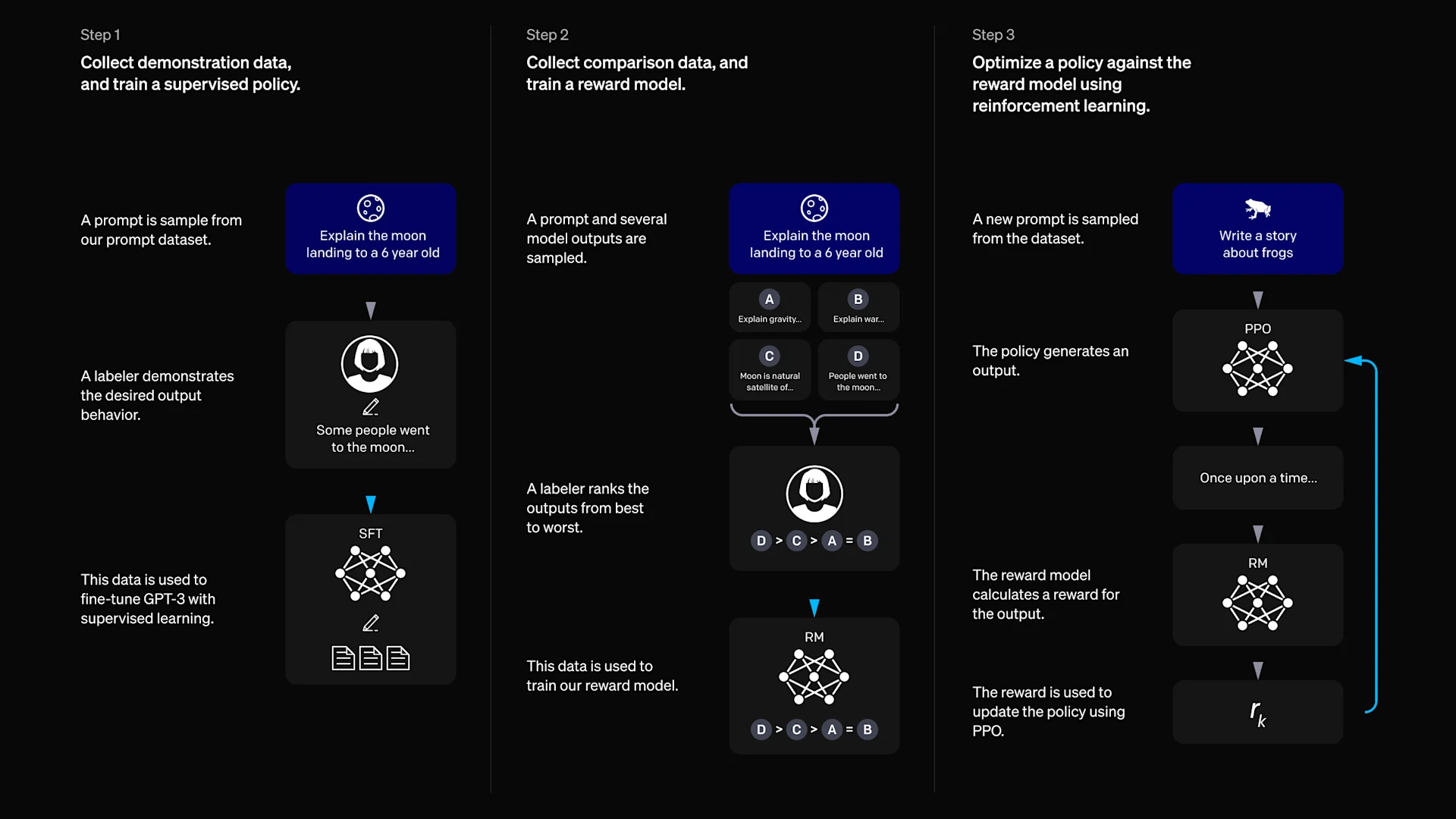
Training Process
InstructGPT models are fine-tuned using reinforcement learning from human feedback (RLHF), a method that leverages human preferences as a reward signal. This process involves collecting human-written demonstrations and labeled comparisons of model outputs on prompts. A reward model (RM) is trained on these preferences and used to fine-tune GPT-3 via the PPO algorithm to maximize alignment.
Capabilities and Efficiency
The training process enhances GPT-3's existing capabilities, unlocking its potential beyond what can be achieved through prompt engineering. However, it doesn’t teach new abilities beyond those learned during pretraining, as the fine-tuning uses only a fraction of the compute and data. This makes it an efficient approach for effectively aligning the model to follow instructions.
Addressing Limitations
While aligning models improves safety and instruction-following, it can introduce an “alignment tax,” reducing performance on certain academic NLP tasks. A mix of original pretraining data is included during RL fine-tuning to mitigate this. This adjustment preserves or even surpasses GPT-3's performance on academic tasks while maintaining alignment.
Method for ChatGPT
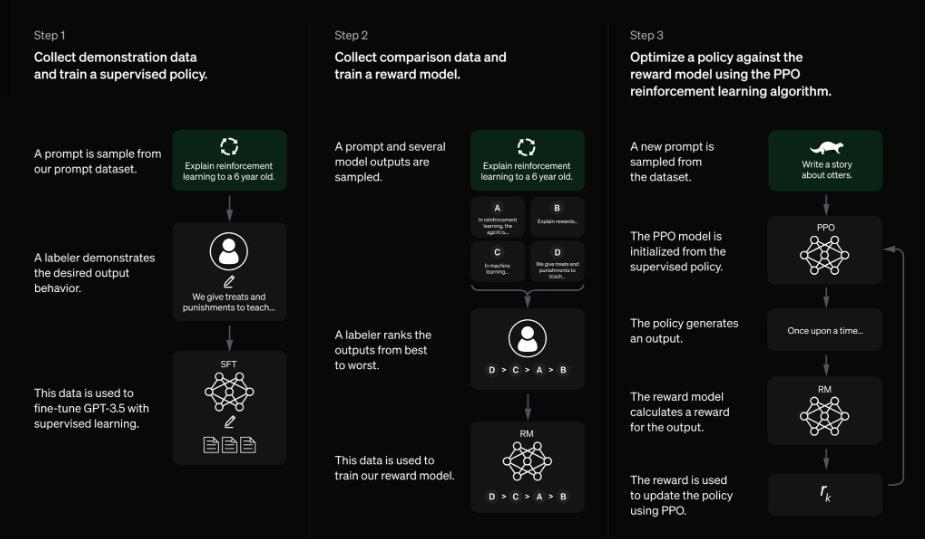
This model was trained using a similar RLHF method as InstructGPT, with slight variations in the data collection process. The approach involved supervised fine-tuning and reinforcement learning using a combination of human AI trainers and a dialogue dataset.
Video Credit: ByteByteGo YouTube
Training Steps
Supervised Fine-Tuning: AI trainers created conversations, acting as both the user and AI assistant, using model-generated suggestions.
Dataset Creation: The dialogue dataset was mixed with the InstructGPT dataset, transforming it into a dialogue format.
Comparison Data Collection: AI trainers ranked model responses for quality, selecting and comparing alternative completions.
Reward Model Development: These comparisons were used to train a reward model that guides the fine-tuning process.
Reinforcement Learning: The model was fine-tuned using Proximal Policy Optimization (PPO) over several iterations.
Unlocking the Power of ChatGPT: Key Features That Elevate Your Experience
Write, Brainstorm, and Edit: Collaborate with ChatGPT on writing, brainstorming ideas, and editing content.
Summarize Meetings: ChatGPT can summarize meeting notes and extract new insights to increase productivity.
Generate and Debug Code: ChatGPT assists with creating code, automating tasks, and learning new APIs.
Learn and Explore: Dive into new topics, hobbies, or answer complex questions with ChatGPT’s assistance.
Web Search: Use the web search feature to get timely answers with relevant links.
Canvas for Collaboration: Work on projects with ChatGPT using an intuitive canvas for edits and revisions.
Data Analysis and Charts: Upload files for data analysis, summarization, and chart creation.
Image Analysis: Upload or ask about images, like identifying details or analyzing visual elements.
Tackle Complex Problems: OpenAI o1 helps reason through complex questions in areas like math, science, and coding.
Create Images: Request image generation based on simple or detailed descriptions.
Apple Partnership: ChatGPT integrated into iOS, iPadOS, and macOS for enhanced experiences.
Limitations of ChatGPT
ChatGPT can occasionally provide answers that sound plausible but are incorrect or nonsensical, primarily due to the lack of a definitive source of truth during its reinforcement learning (RL) training. This is challenging to fix as improving caution leads to the model declining valid answers, and supervised training can be misleading because the model’s knowledge may not align with the demonstrator's.
The model is sensitive to changes in input phrasing, where slight variations in the prompt can result in vastly different responses. It can sometimes fail to recognize when it doesn’t fully understand a question and, instead, guesses at the user’s intent, leading to potential inaccuracies.
Additionally, ChatGPT tends to be excessively verbose and can overuse certain phrases, a side effect of biases in its training data. While efforts have been made to avoid harmful or biased responses, the model may still occasionally generate inappropriate content, and further refinements are ongoing through user feedback and moderation tools.
Elevate your experience. Join our community
Please help us get better and suggest new ideas at ceo@theaisignal.com