

Frontier: OpenAI’s Push to Run AI Agents at Enterprise Scale
Along with Perplexity Introduces Model Council for Multi-Model Verification


TLDR; In Today’s Signal
Meta spins out Vibes as a standalone AI-generated video app
Perplexity Introduces Model Council for Multi-Model Verification
Apple and Google Formalize Gemini-Based Foundation Model Partnership
Anthropic extends Opus into long-context, agentic execution
Tinder deploys AI matchmaking to reduce swipe fatigue
Anthropic attacks OpenAI’s ad strategy in Super Bowl campaign
Benchmark raises $225M to double down on Cerebras
Fibr AI raises $7.5M seed to build agentic web infrastructure
THE AI SIGNAL PICKS
Perplexity Introduces Model Council for Multi-Model Verification
Perplexity launched Model Council, a multi-model research mode that runs a single query across multiple frontier models simultaneously. The feature currently executes prompts across models such as GPT-5.2, Claude Opus 4.6, and Gemini 3.0, then synthesizes areas of agreement and disagreement. This replaces manual cross-checking between models with a single aggregated output inside Perplexity’s core interface. The release formalizes multi-model comparison as a default workflow, signaling rising model divergence and increasing demand for verification at decision time.
Meta spins out Vibes as a standalone AI-generated video app
Meta is testing a standalone Vibes app, separating its AI-generated short-video product from Meta AI. The app offers a dedicated feed where all videos are AI-generated, with remixing tools, music layers, and cross-posting to Instagram and Facebook. This shift repositions Vibes as a direct social video platform competing with OpenAI’s Sora app rather than an assistant feature. Meta also confirmed upcoming freemium subscriptions for Vibes creation, signaling early monetization of AI-native social video.
THE BIG LEAP
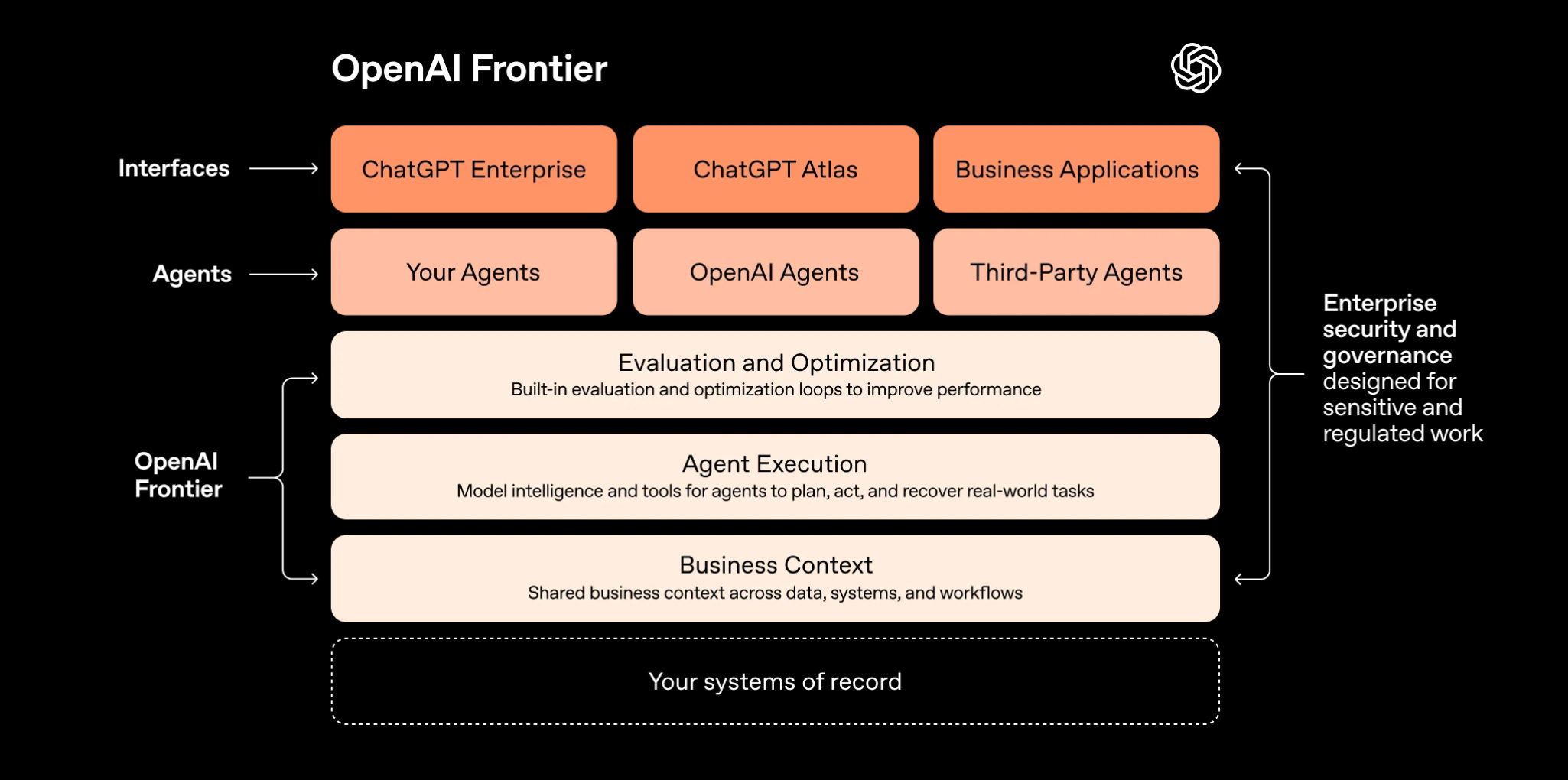
Frontier: OpenAI’s Push to Run AI Agents at Enterprise Scale
Signal Scoop:
OpenAI introduced Frontier, a platform to build, deploy, and manage AI agents that perform real work across enterprises. Unlike prior agent tools, Frontier focuses on production readiness: shared context, permissions, evaluation, and execution across systems. Early adopters include HP, Oracle, State Farm, Uber, and Intuit.
The Full Picture:
Frontier targets the deployment gap between model capability and enterprise execution.
Platform supports end-to-end agent lifecycle: onboarding, context sharing, execution, evaluation, and optimization.
Agents operate across existing data warehouses, CRMs, internal tools, and multi-cloud environments without replatforming.
Built-in identity, permissions, and governance enable use in regulated and sensitive workflows.
Early enterprise use cases show material gains: 6-week processes reduced to 1 day, 90% sales time reclaimed, and up to 5% production output increases.
What You Can’t Miss:
Frontier shifts OpenAI from model supplier to enterprise operating layer for AI labor. Control is moving from isolated copilots to managed AI coworkers embedded across workflows. Companies that standardize agent deployment gain speed, leverage, and compounding productivity. Those without an execution layer risk falling behind as AI advantage concentrates around who can reliably run agents in production.
Anthropic extends Opus into long-context, agentic execution
Signal Scoop:
Anthropic released Claude Opus 4.6, adding materially stronger agentic coding, long-context stability, and a 1M-token context window (beta).
The change is not incremental accuracy, but durability: the model maintains reasoning quality across longer, more autonomous tasks.
The Full Picture:
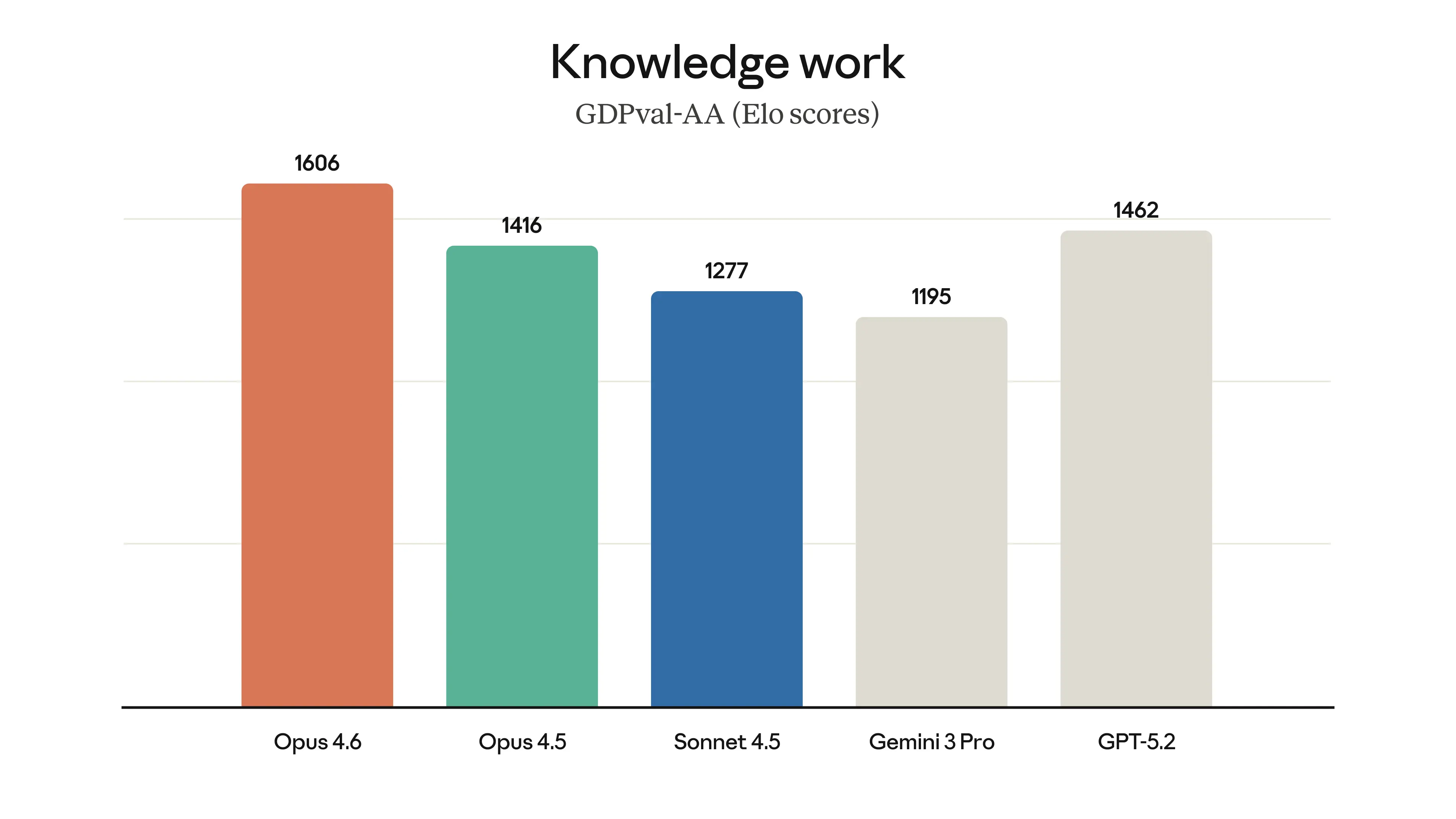
Ranks first on Terminal-Bench 2.0 for agentic coding and Humanity’s Last Exam for multidisciplinary reasoning.
On GDPval-AA, exceeds the next-best frontier model (GPT-5.2) by ~144 Elo points; improves ~190 Elo over Opus 4.5.
Supports a 1M-token context window (beta) and up to 128k output tokens; standard pricing unchanged below 200k tokens.
Long-context retrieval improves sharply: 76% on MRCR v2 (1M-token variant) versus 18.5% for Sonnet 4.5.
Adds system-level controls: adaptive thinking, four effort settings, context compaction for long-running agents, and multi-agent coordination in Claude Code (preview).
Safety evaluations show misalignment rates comparable to or lower than prior Opus models.
What You Can’t Miss:
Opus 4.6 shifts the frontier from short-horizon reasoning to sustained cognitive throughput. Reliable use of very large context reduces failure modes that previously limited autonomous agents, especially in large codebases and document-heavy workflows. This concentrates advantage at the layer where models must operate continuously without degradation, increasing pressure on competitors whose performance drops as context length and task duration grow.
GPT-5.3-Codex collapses coding, computer use, and professional work into one agent
Signal Scoop:
OpenAI introduced GPT-5.3-Codex, a new agentic model that merges frontier coding performance with general professional computer use. It outperforms GPT-5.2-Codex across key benchmarks while running ~25% faster. This marks a shift from “coding assistant” to “end-to-end work agent.”
The Full Picture:
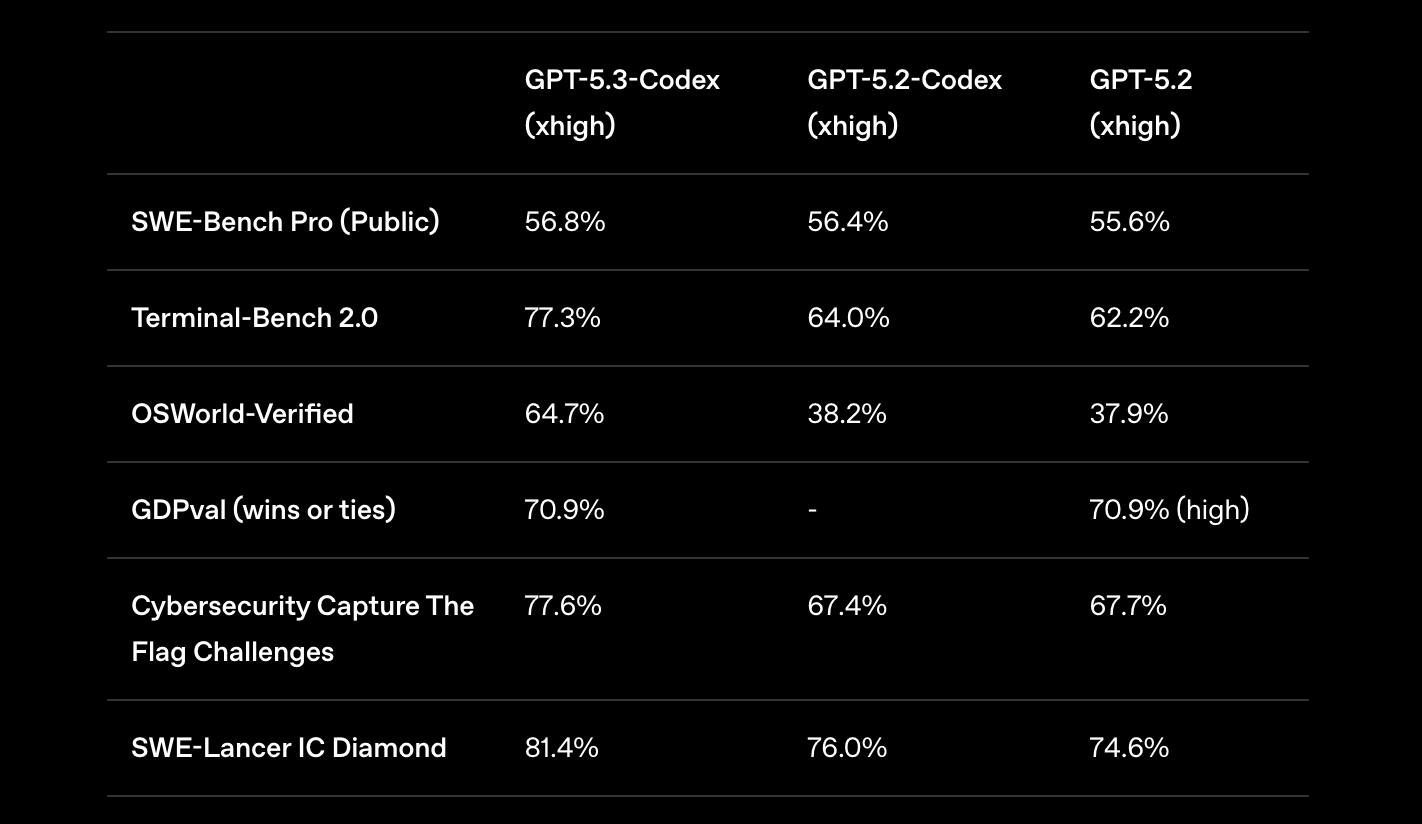
Sets a new industry high on SWE-Bench Pro (56.8%) and Terminal-Bench 2.0 (77.3%), surpassing prior Codex models.
Achieves 64.7% accuracy on OSWorld-Verified, approaching human performance (~72%) in real desktop task completion.
Matches GPT-5.2 on GDPval (70.9% wins or ties), covering 44 professional knowledge-work roles beyond software engineering.
Demonstrates lower token usage than previous models, enabling longer autonomous runs with less cost overhead.
Classified as High capability in cybersecurity, with dedicated training for vulnerability identification and expanded defensive safeguards.
What You Can’t Miss:
This release shifts leverage from tools to integrated agents that reason, build, and execute end-to-end. Coding stops being the constraint; orchestration becomes the differentiator. Teams gain speed, scope, and labor compression, forcing competitors to bridge the gap between code generation and real computer operation. Advantage now sits at full-stack agent control, not raw model IQ.
ON THE AI EDGE

Tinder deploys AI matchmaking to reduce swipe fatigue.
Tinder is testing an AI feature called Chemistry that replaces mass swiping with question-driven matching and optional camera-roll analysis. The system delivers a limited set of recommendations instead of infinite profiles, reframing discovery around intent rather than volume. Parent company Match Group reports the shift as subscriber growth and MAUs decline, with new registrations down 5% and MAUs down 9% year over year. AI-led discovery and verification features now anchor Tinder’s engagement and revenue recovery strategy.Anthropic attacks OpenAI’s ad strategy in Super Bowl campaign.
Anthropic is spending millions on Super Bowl ads mocking plans to introduce advertising into ChatGPT, positioning Claude as ad-free. The 30-second spot airing on NBC states “Ads are coming to AI. But not to Claude,” directly targeting OpenAI’s monetization shift. OpenAI CEO Sam Altman publicly called the ad deceptive as OpenAI runs its own Super Bowl campaign for Codex. The clash surfaces as both labs, neither profitable, compete for users, enterprise contracts, and IPO attention.
AI START-UP NEWS
Andreessen Horowitz raised $15B, carving out $1.7B for AI infrastructure.
Andreessen Horowitz closed a new $15B fund, with $1.7B allocated to its infrastructure practice backing AI platforms. The capital supports companies across model tooling, inference, and search infrastructure, including OpenAI and ElevenLabs. The fund size and earmark exceed prior cycles, reflecting higher capital intensity as model scale, compute demand, and infra-level competition accelerate.Benchmark raises $225M to double down on Cerebras.
Benchmark Capital raised $225M across two special-purpose “Benchmark Infrastructure” vehicles to participate in Cerebras Systems’ $1B round. The financing priced Cerebras at $23B, nearly tripling its valuation in six months as demand for non-GPU AI compute accelerates. Cerebras’ wafer-scale systems target faster training and inference by eliminating multi-chip data bottlenecks. The move concentrates capital behind alternative AI infrastructure suppliers competing with Nvidia while positioning Cerebras ahead of a planned 2026 IPO.Fibr AI raises $7.5M seed to build agentic web infrastructure.
Fibr AI closed a $7.5M seed round led by Accel with participation from WillowTree Ventures and MVP Ventures. The company is building an agentic web experience layer where every URL adapts in real time using context, intent, and behavioral signals. The platform integrates ad, CRM, and onsite data to dynamically rewrite content, flows, and visuals per visitor. Early pilots report ~20% conversion lifts, positioning Fibr as infrastructure for post-click personalization as traffic shifts toward AI-driven agents.Elevate your experience.
Join our community
Please help us get better and suggest new ideas at ceo@theaisignal.com