

AI Evals: What They Are, Why They Matter, and How to Build Them
With all the information on AI Evals under one roof


Today, we’re diving deep into AI Evals—what they are, why they’re broken, who’s trying to fix them, and how you should be thinking about evaluation as a core product discipline in the AI era.
What are AI Evals, and why do they matter?
AI evaluations—known as AI evals —are sophisticated, structured protocols designed to rigorously assess AI systems. Unlike simplistic pass/fail benchmarks, robust eval frameworks operationalize abstract goals (“enhance user satisfaction”) into quantitative, reproducible performance standards that closely mimic how systems behave under real-world conditions. Without such mechanisms, deployments become blind gambles; surface-level metrics may look promising, but real user interactions often reveal critical failure modes.
Without them, you're flying blind—releasing updates that look great in dashboards but fail woefully in user hands.
Without reliable evals, you’re shipping into the void.
In theory, evals answer:
Is my model aligned with user intent?
Does it hallucinate less than the last one?
Is it useful, safe, and trustworthy?
In practice, though, evals often tell us:
Whether it passed a standardized benchmark (some of which are years old)
How it scored on static tasks (that users never do in real life)
Or worse, a handpicked cherry of qualitative outputs
If you’ve ever wondered why AI tools sometimes feel “great on paper, but bad in practice”—evals are often the root cause.
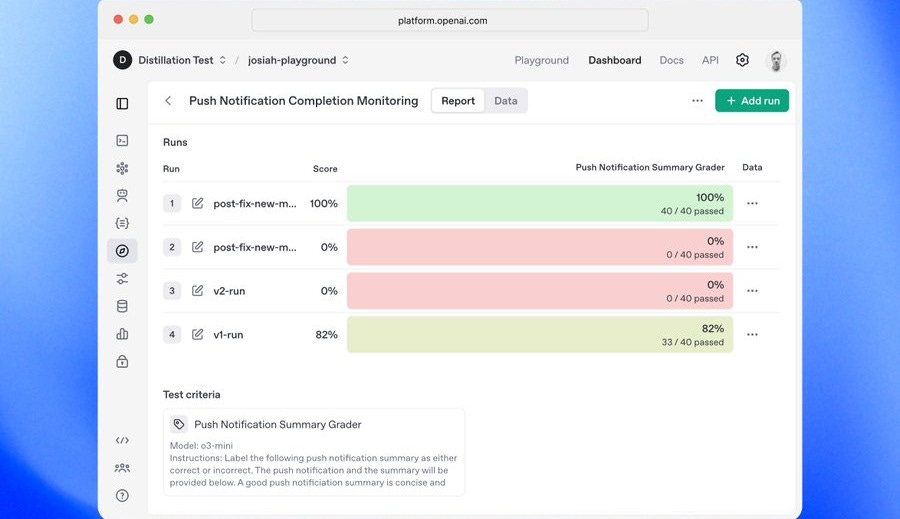
Why current AI evals are broken
Despite the growing sophistication of generative AI systems, the evaluation infrastructure tasked with measuring their capabilities has lagged significantly behind. Today’s dominant evaluation practices suffer from structural flaws that make them ill-suited for high-stakes, real-world applications. Here’s a breakdown of what’s broken and why it matters:
Benchmarks ≠ Reality
The Problem: Modern benchmarks (e.g., GSM8K, ARC, MMLU, Big-Bench) were instrumental in catalyzing early model progress, but they now function more like academic contests than real-world stress tests. Models that perform well on these benchmarks often overfit to narrow question distributions, exploiting lexical patterns or shortcut solutions that don’t generalize to operational settings.
Why It Fails in Practice:
Synthetic vs. Natural Distribution Gap: Benchmarks are often synthetic and disjoint from the naturally noisy, multi-modal, and user-specific queries encountered in deployment.
Benchmark Saturation: State-of-the-art models routinely surpass human baselines, suggesting we've hit ceiling effects that obscure real differentiators.
Adversarial Blind Spots: These benchmarks fail to account for jailbreaking, subtle prompt attacks, or shifting socio-linguistic context, all of which degrade safety in production.
Narrow, Static, and Misaligned with Real User Needs
The Problem: Most eval suites narrowly assess factual recall, syntactic validity, or multiple-choice task accuracy. But real-world use cases demand end-to-end task competence, often involving reasoning across modalities, understanding goals, and integrating APIs, databases, or business logic.
Why It Fails in Practice:
Task Completion ≠ Knowledge Recall: A high score on MMLU or TriviaQA means little if the model can't fill out a tax form or write a GDPR-compliant email.
Static Context: Evaluation on isolated prompts doesn’t capture how models behave in multi-turn, persistent user interactions.
Skill-to-Task Mapping Gap: Benchmarks rarely measure executional robustness—e.g., handling malformed input, recovering from ambiguity, or maintaining persona consistency across a session.
Poor Scalability with Model Lifecycle and Deployment Velocity
The Problem: Manual evaluations—ranking outputs, scoring generations, red-teaming, or scenario crafting—are not only labor-intensive but also non-scalable. As teams move to rapid iteration cycles with weekly or even daily model pushes, eval pipelines must evolve to match CI/CD cadences.
Why It Fails in Practice:
Latency and Labor Bottlenecks: Human-in-the-loop evals can't keep pace with high-frequency fine-tuning or prompt engineering changes.
Eval Debt Accumulation: Teams often ship updates without complete re-evaluation, leading to “silent regressions” in performance or safety.
Dynamic Distribution Drift: As user input patterns evolve, test sets must be continually rebalanced and updated to reflect actual usage.
Disconnection from Product and Business Metrics
The Problem: Current evaluation frameworks are divorced from business impact. They optimize for metrics that feel rigorous but don't tie to outcomes that product managers, operations teams, or executives care about—like support ticket deflection, user conversion, trust, retention, or latency reduction.
Why It Fails in Practice:
Siloed Evaluation Objectives: Engineering evaluates “does the model work,” but product cares about “does it move the needle.”
Lack of Metric Grounding: A model may show 3% accuracy gain on SQuAD but generate 12% more escalations in customer support.
No Feedback Loop to Product Decisions: Changes in model architecture, prompting, or data sources are rarely evaluated against actual KPIs.
Real Consequences of Broken Evals
False Confidence: Models that ace benchmarks get greenlit, even when their behavior under real-world stressors is erratic.
Slow-to-Detect Failures: Post-launch regressions only surface through user complaints or incident reports—not proactive evals.
Blocked Trust from Stakeholders: Leadership, legal, and compliance teams are unable to verify model readiness due to opaque, technical-only metrics.
What Great AI Evals Look Like
High-quality AI evaluations are not just passive scorecards—they’re integral components of the development and deployment lifecycle. Effective eval systems are goal-aligned, multi-layered, and fully operationalized. Below is a blueprint of what separates best-in-class AI evals from superficial checks.
Top-Down Principal Design: Evaluation Grounded in Product Purpose
At the core of any meaningful evaluation system is the precise articulation of the model's job-to-be-done. Without this, evals tend to drift toward abstract performance metrics that have little bearing on business utility or user experience.
Principles:
Define success in task-specific, operational terms.
“Support chatbot resolves billing inquiries with ≥ 92% validated resolution accuracy.”
“Contract summarizer retains ≥ 95% of high-salience legal clauses across jurisdictions.”
Avoid generic metrics like “is helpful” or “improves productivity” unless they’re concretely mapped to observable behaviors.
Establish task completion criteria, not just correctness proxies (e.g., Is the invoice generated successfully? Did the user confirm satisfaction?).
This design principle ensures that evaluation fidelity tracks the actual value proposition the AI is expected to deliver.
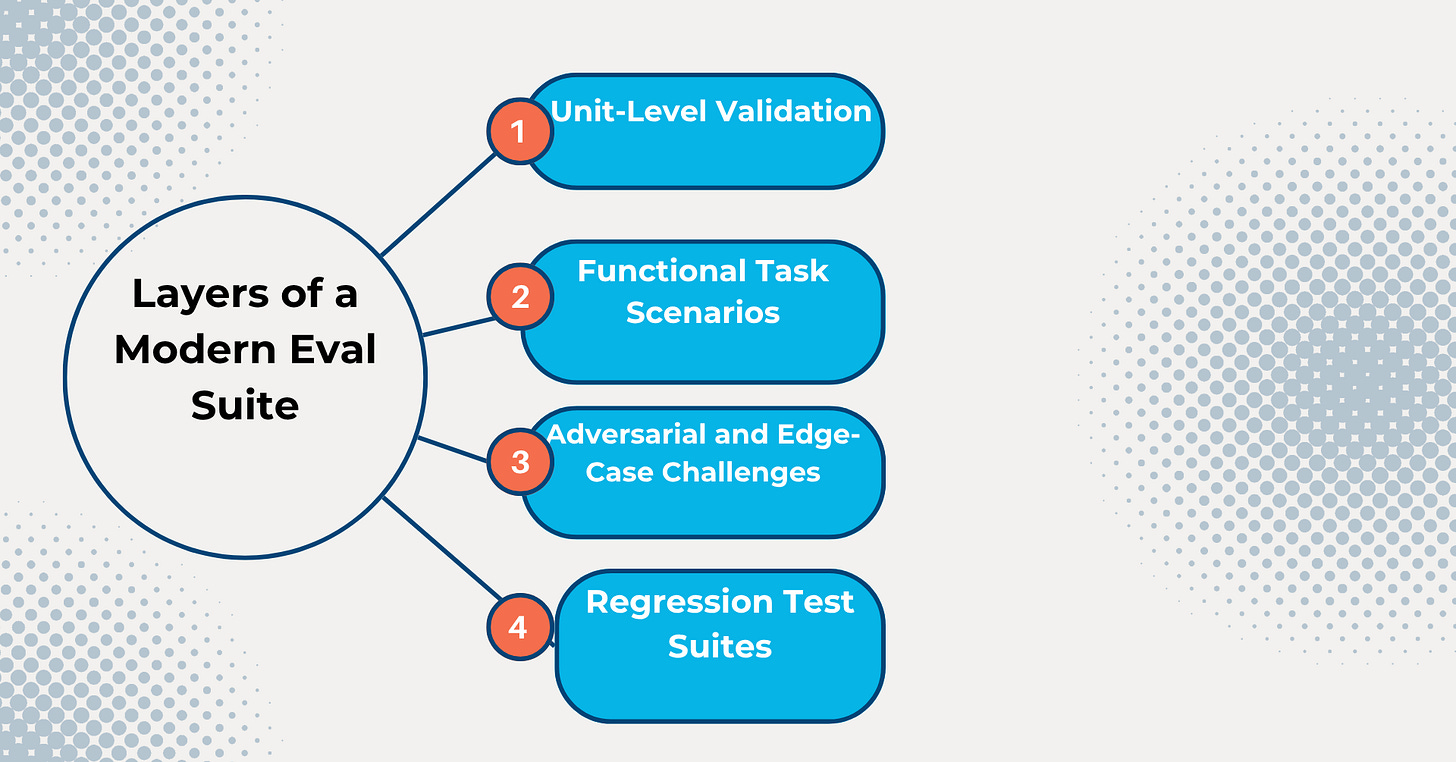
Stratified and Modularized Test Suites
Evaluation is not one-size-fits-all. Robust eval systems use a stratified hierarchy of test types, each probing different aspects of model behavior—from syntax correctness to multi-turn dialogue consistency and failure recovery.
Layers of a Modern Eval Suite:
Unit-Level Validation
Tests input sanitization, structural formatting, adherence to constraints (e.g., date formats, code syntax).
Crucial for foundational correctness and pipeline integration.
Functional Task Scenarios
Simulates real-world usage patterns: long-form inputs, multi-step instructions, ambiguous prompts.
Often modeled as scripted interactions or user simulators.
Adversarial and Edge-Case Challenges
Inject malformed input, prompt injection attempts, or language-specific traps to evaluate model resilience.
Important for red-teaming and safety benchmarking.
Regression Test Suites
Ensure new model versions do not reintroduce prior failure modes.
Essential for CI/CD gating in production environments.
Task Chaining Tests (Optional but Emerging)
Evaluate performance across workflows involving multiple AI agents or modular subsystems (e.g., tool use + summarization + form fill).
Each test suite should be modular, version-controlled, and updatable based on usage telemetry and newly observed behaviors.
Hybridized Scoring Architectures: Automation Meets Judgment
Effective scoring blends speed, scale, and nuance. No single evaluation method suffices; instead, leverage a layered evaluation pipeline combining:
Automated Rule-Based Scorers
Instantly catch objective violations (e.g., invalid output length, incorrect HTML tags, off-topic generation).
Suitable for scalable hard constraints.
LLM-Based Raters or Critique Chains
Use large models to rate outputs on axes like clarity, factuality, coherence, or alignment with intent.
Can scale well, especially with fine-tuned critic models or structured rubrics.
Human-in-the-Loop Evaluation
Blind annotators assess subjective qualities: emotional tone, implied bias, subtle hallucination, legal compliance.
Often used to calibrate LLM raters or resolve edge cases.
Aggregated Dashboards
All scores, metadata, error examples, and confidence intervals should feed into centralized dashboards.
Enables stakeholders (engineering, product, safety, legal) to track regressions, outliers, and ROI trends.
Model-Gated Deployments: Eval-Informed Release Control
One of the hallmarks of mature MLOps organizations is embedding evaluation into the deployment pipeline, such that poor model behavior blocks release, automatically.
Implementation Tactics:
CI/CD Integration of Eval Checks
All model updates (e.g., new weights, prompting logic, tool interfaces) trigger a full re-eval suite before staging or production rollout.
Policy-Based Deployment Gates
Define hard thresholds per task or vertical, fail if factual accuracy < 95% on critical documents
Fail if hallucination rate exceeds baseline + 2%
Safety/Compliance-Linked Eval Layers
Especially in finance, healthcare, or legal contexts, enforce gating through red-teaming, bias tests, and explainability checks.
Logs must be auditable for regulatory or legal discovery (e.g., GDPR, AI Act).
Canary and Shadow Deployment Testing
Run new models alongside production traffic with metrics mirrored but not affecting users.
Used to monitor live behavior drift before full switch-over.
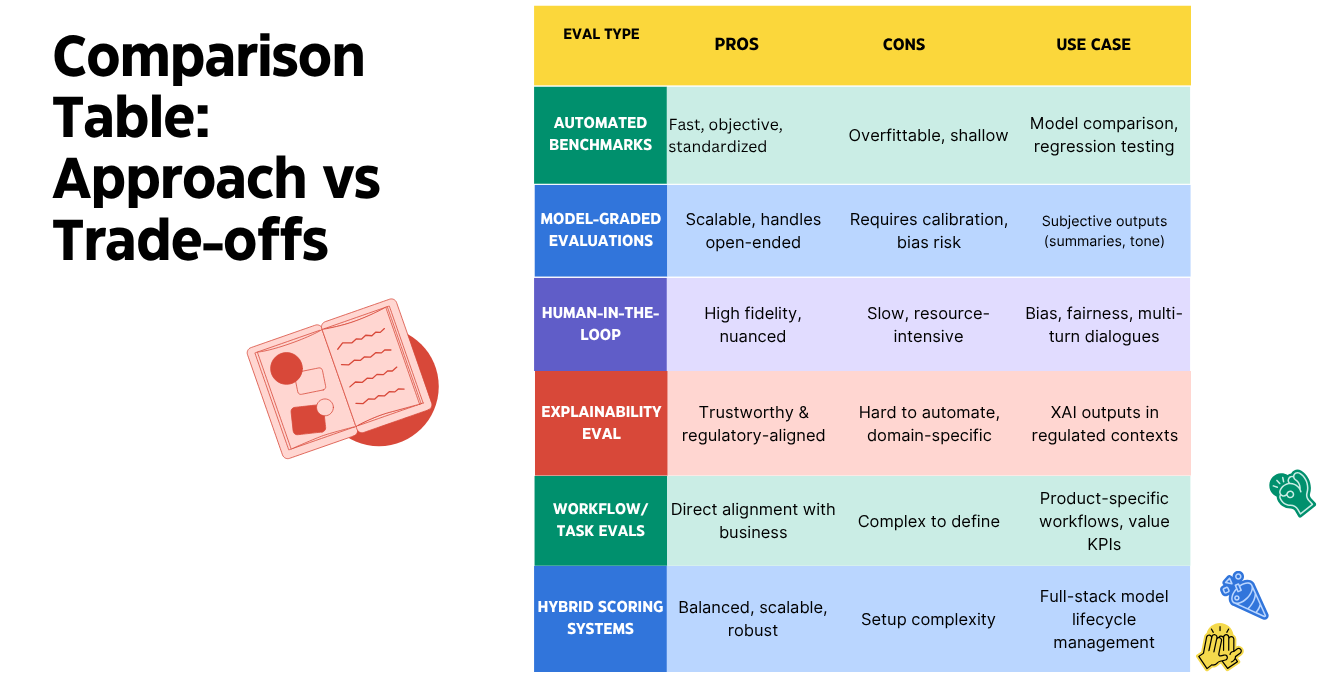
Different Eval Approaches
Automated Benchmarks (Closed-Form, Deterministic)
These evals use standard datasets and objective scoring methods to compare model outputs against ground truths.
Example benchmarks: GSM8K (math reasoning), MMLU (multidomain tasks), BIG‑Bench, FrontierMath, Humanity’s Last Exam, RE‑Bench
Limitations: Easily gamed, quickly saturated as models improve, and often disconnected from real-world workflows
Model-Graded Evaluations (AI-as-Judge)
Workflow: Prompt Model A → Generate output → Prompt Model B (judger) with rubric to score the output
Pros: Scalable, useful for open-ended tasks with no fixed ground truths.
Cons: Requires human oversight to calibrate graders; risk of systemic biases.
Human-in-the-Loop (HITL) Evaluations
Involve human reviewers to provide nuanced, subjective feedback on AI outputs (e.g., coherence, tone, fairness).
Use cases: Dialog systems, creative generation, bias/fairness checks.
Workflow: Reviewers label or score outputs following detailed guidelines, often in blind setups
Challenges: Costly, scales slowly; sampling or proxies (LLM‑based) often used to scale while retaining fidelity
Explainability & XAI Evaluations
Focus on the interpretability and transparency of model reasoning, especially when deployed in high-stakes domains (e.g., healthcare).
Frameworks:
Human-grounded evaluation: Lay users rate explanation clarity and usefulness.
Application-grounded evaluation: Domain experts (e.g. clinicians) assess explanations severity and fidelity.
Functionally-grounded evaluation: Statistical proxies like fidelity, consistency, and plausibility
Emerging frameworks: The System Causability Scale (SCS) provides human‑usable scoring for explanation quality
Task-Oriented and Workflow Evals
Evaluate models on end-to-end workflows that matter for your product—like customer support resolution, document summarization, or code synthesis.
Components:
Functional steps (multi-turn/dialog states).
Adversarial cases and regression cams.
Performance impact: support case reduction, user retention, error rates.
Purpose: Align model output with business objectives, not just correctness.
Hybrid Scoring Systems
Combine automated, model-graded, and human-review mechanisms into a unified scoring pipeline.
Examples:
Use automated match/fuzzy JSON match for structured tasks.
LLM-based grading for qualitative tasks.
Human blind review for edge-case nuance.
Platforms: OpenAI Evals, Pydantic Evals, Structured‑Evals, DeepEval, Opik, Lighteval and others support this layered workflow
Operationalizing Evals in Teams
Translating eval strategy into production-grade reality requires robust workflows, clear ownership, and seamless tooling. Great evaluations aren’t just a research function—they’re an orchestrated collaboration across engineering, product, data science, safety, and GTM teams. Here's how elite teams embed AI evals into their development and delivery lifecycle:
Model-Gated Deployments: Evals as Deployment Firewalls
In high-stakes environments, model evaluation must act as an automated policy enforcement layer within CI/CD systems. This ensures no version of the model ships unless it meets pre-defined functional and safety criteria.
CI-integrated validation gates: All model updates trigger a full regression and capability re-evaluation.
Blocking deploys on performance dips, bias spikes, or safety violations.
Supports differential testing: Only changes are re-evaluated, preserving velocity.
Ideal for regulated verticals (e.g., financial NLP, healthcare assistants, legal summarizers) where compliance is not optional.
This prevents the classic failure of “ship now, fix later” in AI systems—an approach that can lead to hallucinations, legal exposure, and degraded UX at scale.
Evaluation Dashboards: Building a Culture of Observable Quality
Centralized dashboards transform evaluations from isolated test results into shared organizational truth. This transparency allows for better decisions, trust-building, and continuous improvement.
Real-time dashboards surface pass/fail ratios, hallucination rates, bias scores, and task-specific success metrics.
Segment results by model version, user persona, or content type (e.g., creative writing vs. legal docs).
Enable non-technical stakeholders—PMs, QA, execs—to make data-driven decisions about launches or rollbacks.
Integrate with internal alerting systems (e.g., Slack, PagerDuty) when key thresholds degrade.
Dashboards are not just for QA—they are a product and growth lever that fosters accountability and shared ownership.
EVP (Evaluation Value Proposition): Linking Model Quality to Business ROI
Too often, model quality is measured in technical terms only. Instead, forward-thinking orgs define an Evaluation Value Proposition (EVP)—clear articulation of how improvements in model behavior map to business value.
Does reduced hallucination translate to fewer support escalations?
Does better summarization increase content consumption or user retention?
Does improved safety handling reduce legal risk and moderation costs?
This ROI mapping transforms evals from "technical diligence" to strategic growth levers. PMs, marketers, and finance leaders need this language to prioritize roadmap decisions, pricing, and positioning.
The Challenges We Face
Despite the promise of structured evaluation frameworks, real-world AI evals face systemic challenges rooted in scale, ambiguity, and operational drift. Below are the most pressing complexities practitioners must account for:
Infinite Scenario Space: Prioritizing High-Leverage Failure Domains
The fundamental nature of AI—especially in open-domain language or vision models—means the input space is effectively unbounded. Exhaustive testing is infeasible. Instead, successful teams focus on identifying:
High-leverage failure points: Common user intents, known weak spots (e.g., numeracy, temporal reasoning), and regulated use cases.
Risk-weighted test coverage: Prioritize scenarios that amplify business, safety, or compliance risk.
Task-specific slices: Rather than general benchmarks, evaluate performance across personas, formats, and complexity tiers (e.g., legal writing vs. informal speech).
Human Evaluation Bottlenecks: Scaling Beyond Manual Review
Human-in-the-loop (HITL) review is still the gold standard for nuance, subjective quality, and edge-case judgment. However, it's inherently costly, slow, and inconsistent. Teams mitigate this with hybrid approaches:
LLM-based scoring proxies: Use trusted models (e.g., GPT-4, Claude 3 Opus) to judge relevance, coherence, or factuality—then calibrate with humans.
Active sampling: Evaluate only informative slices (e.g., high entropy or low confidence samples), reducing volume without sacrificing insight.
Crowd-labeled panels: Use distributed review networks (e.g., Surge AI, Amazon Mechanical Turk) with templated evaluation rubrics.
Dataset Drift and Label Staleness: The Hidden Threat to Eval Integrity
Evaluation datasets must evolve with product usage, or they risk becoming obsolete. Common causes of drift:
Behavioral evolution: Users shift how they interact with AI systems—new task formats, intents, or edge behaviors arise.
UX changes: Updates to prompt engineering, UI affordances, or task framing can invalidate earlier test cases.
Model-influenced behavior: The model’s own responses change user expectations, requiring ongoing feedback-loop tuning.
Continuous dataset curation is required:
Re-sample from live logs (with anonymization/privacy filters).
Apply differential testing against production telemetry to catch decoupling.
Maintain versioned datasets with clear lineage (e.g.,
EvalSuite_v1.3.json).
Bias and Safety: Dual Compliance Fronts with Distinct Failure Modes
Bias and safety failures are not just QA issues—they’re PR, legal, and ethical liabilities. These domains often overlap but must be evaluated independently:
Bias Detection: Systematically test for disparate outcomes across protected attributes (race, gender, region, etc.). Use templates, fairness slices, and counterfactuals.
Safety Audits: Validate model behavior under adversarial prompts (e.g., self-harm, misinformation, jailbreaks). Monitor toxicity, incitement, and manipulation vectors.
Emerging Best Practices
Modular Test Suites
Design your evaluation infrastructure as a composable and modular system. By decomposing tests into categories like syntax validation, task execution, safety constraints, and UI consistency, you can ensure that new model variants or architectures can be evaluated without rewriting the entire suite.
This abstraction allows teams to plug-and-play different models while preserving test relevance and comparability.
Think of it like unit tests for models—portable, extendable, and reusable across architectures.
Performance Thresholds
Set explicit, measurable performance gates (e.g., "≥ 90% accuracy on key tasks", "≤ 1% toxic outputs") that must be met before a model progresses from staging to production.
These thresholds serve as guardrails and eliminate ambiguity in deployment decisions.
Integrate them into CI/CD systems with alerting and rollback mechanisms when thresholds are breached.
This enables objective go/no-go decisions during deployment.
Continuous Regression Testing
Model performance can degrade over time—due to changes in upstream data, retraining anomalies, or drift in user behavior.
To mitigate this, implement automated regression testing pipelines that run evaluations on every model iteration, update, or retraining cycle.
This ensures previously resolved issues don't resurface, and that evolving models don’t introduce silent regressions.
Regression tests are your safety net against the law of unintended consequences.
Shared Ownership Culture
Embed eval accountability into your organizational DNA:Onboarding: New engineers and PMs should be trained on your eval philosophy and infrastructure.
OKRs: Teams should own eval pass rates as part of their quarterly goals.
Rituals: Include eval metrics in weekly model reviews, demos, or incident postmortems.
This ensures that evaluation quality is not relegated to a niche ML team—it becomes a shared cross-functional responsibility spanning engineering, product, safety, legal, and QA.
The best eval culture is one where failures are caught and resolved before users ever see them.
AI “evals” are quietly becoming the single biggest divider between random AI play and rock-solid, enterprise-grade AI. These structured tests go far beyond benchmarks; they form the backbone of reliable, safe, and repeatable AI systems. Ignore them at your peril.
Read More
AI Evals: https://www.thoughtworks.com/en-in/insights/decoder/a/ai-evals
OpenAI Evalshttps://github.com/openai/evals
About AI Evals: https://news.ycombinator.com/item?id=44430117
Gen AI evaluation service overview: https://cloud.google.com/vertex-ai/generative-ai/docs/models/evaluation-overview
Paradigms of AI Evaluation: https://arxiv.org/html/2502.15620
Why Evals are Important: https://blog.cloudnueva.com/why-evals-are-important-in-ai-development
Mastering Openai’s Evals: https://www.technicalexplore.com/ai/mastering-openais-evals-a-comprehensive-guide-to-evaluating-large-language-models
Evals-Openai’s framework for evaluating LLMs: https://datanorth.ai/blog/evals-openais-framework-for-evaluating-llms
Elevate your experience. Join our community
Please help us get better and suggest new ideas at ceo@theaisignal.com